In November, Julie Culp, a school counselor in Tennessee created a selfie as part of a lesson plan to teach her fifth grade students about how quickly a photo they upload might spread around the internet via social media and other platforms. The aim being to demonstrate that even if you think a photo is tucked away in a private part of the Internet it can easily escape and spread to users you may not wish to share that photo with. Culp’s snapshot has been shared and liked hundreds of thousands of times and perhaps by now (following massive media interest) seen by millions of people.
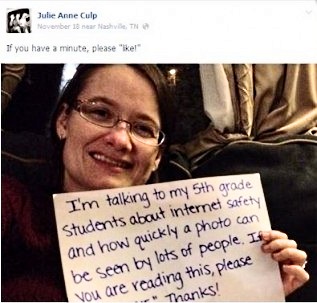
Such anecdotes involving how a piece of information in the form of a photo, a video clip or app can go “viral” are common fodder for the technology pundits in the media. However, interesting and entertaining as such phenomena are it is also important to have more controlled research into the nature of Internet virality. Writing in the International Journal of Communication Networks and Distributed Systems, Lotfi ben Othmane and Harold Weffers of the Department of Mathematics and Computer Science, at Eindhoven University of Technology in The Netherlands, working with Pelin Angin and Bharat Bhargava of the Department of Computer Science, at Purdue University, in West Lafayette, Indiana, USA, explain how they have developed a mathematical model for how the degree of privacy associated with a given piece of information changes over time as it is disseminated through online social networks.
The researchers point out that as many people share private information with their friends and relatives via online social networks (OSNs) they assume that the reach of any given “share” is limited. However, network analysis suggests that almost any shared information will eventually reach all users of the network because these systems exhibit “small-world” behaviour. By definition: a small-world network is a graph of interconnected nodes wherein each node is connected to the others via a small number of steps even if the nodes are not near neighbors. This is the root of the much-vaunted six-degrees of separation phenomenon in which we (the network’s nodes) are all seemingly connected to each other through at most six or so connections whether you live in Arizona or Ankara, Zanzibar or Zagreb.
However, any more than a superficial look at an online network, such as Facebook or Twitter, reveals that the strength of connections between the nodes, the users, of such systems and how many connections there are to and from each user, can affects the rate at which a given piece of information will flow through the network. If CNN or the BBC shares a piece of information with its “followers” that information is likely to spread rapidly throughout the network especially in comparison with a piece of information originally shared by a humble technology blog, such as Sciencetext. Moreover, for individuals sharing information there is a saturation point at which privacy does not vanish entirely, there are some nodes or users that may never see your embarrassing update, but it will nevertheless reach the majority of users at some point in time.
A moral of an earlier tale, as I’ve said time and time again might be: “If you don’t want it on the Internet, don’t put it on the Internet”. Of course, things have changed in Google StreetView, NSA world, post-Snowden, but there is some hope, mathematically speaking that even if you reveal all online there will be someone, somewhere who never gets to see your information. As with Ms Culp’s photo, there are probably a few less than well-connected users, somewhere…maybe in Arizona maybe in Zagreb who are yet to see her smiling face and her viral message!
![]() Othmane L.B., Weffers H., Angin P. & Bhargava B. (2013). A time-evolution model for the privacy degree of information disseminated in online social networks, International Journal of Communication Networks and Distributed Systems, 11 (4) 412. DOI: 10.1504/IJCNDS.2013.057719
Othmane L.B., Weffers H., Angin P. & Bhargava B. (2013). A time-evolution model for the privacy degree of information disseminated in online social networks, International Journal of Communication Networks and Distributed Systems, 11 (4) 412. DOI: 10.1504/IJCNDS.2013.057719