Computer scientists in India have developed a new kind of news aggregator that pulls in multiple sources of news, ranks them according to your search criteria (keywords) and generates a contextual summary for each of the items likely to be most important to you. The team claims their system addresses the three main problems facing news aggregation services – scaleability, reliability and fault tolerance – by working in the cloud and with the necessary processes operating in parallel on the numerous news inputs.
Arockia Anand Raj and Mala of the Anna University in Chennai, explain how many users are now overwhelmed by news sources despite the best efforts of current aggregators to file and filter stories based on user interests and even in the wake of Reddit, Twitter and other crowd and citizen journalism efforts. Technically, their new system CloudPress 2.0 exploits the MapReduce paradigm. MapReduce is a programming model that allows large data sets to be processed using distributed computing on clusters of computers, something for which Google is renowned. It also uses Lucene-based indexing. Apache Lucene is a free/open source information retrieval software library, which can be used for any full-text indexing applications and has been most widely used by Internet search engines and local, single-site searching applications.
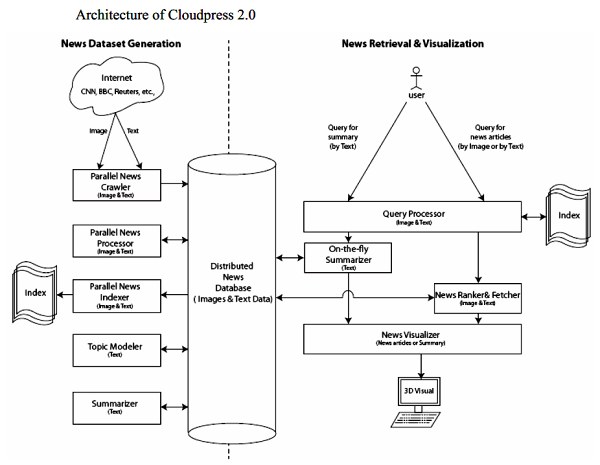
The overall system architecture combines two processes : news dataset generation and news retrieval and visualization, the team explains. “News dataset generation involves fetching, processing, indexing, topic modelling and summarising news articles,” they explains. “News retrieval and visualisation involves query processing, on-the-fly summarising, ranking and retrieving of news from the distributed database and finally, visualising it as 3D visual.”
The team has pitted their system against the Ubicrawler and Mercator news aggregator systems and found that CloudPress 2.0 takes approximately half the time as those two to process news inputs where each URL might contain 100 or more links so there are several hundred URLs to be processed. Indeed, with 500 URLs, CloudPress processes them all in about 30 seconds, whereas Mercator and Ubicrawler take almost a minute to do the same processing. Pre-processing and Lucene indexing more than half the time taken to search an unindexed test database and cut the search times by 30 or 40% compared with a conventionally indexed database.
The next step will be to extend CloudPress 2.0 to the retrieval of news in the form of videos and audio and the development of ways to abstract a summary from those sources too.
“Cloudpress 2.0: a new-age news retrieval system on the cloud” in Int. J. Information and Communication Technology, 2013, 5, 150-166